Data import
Mit der lisr::get_lis_pop() Funktion werden die
Bevölkerungsdaten eingelesen. Das Argument rubrik_nr kann
die folgenden Werte annehmen:
- 1 (Einwohner; Residents)
- 2 (Einwohner nach Alter; Residents by age)
- 3 (Wohnberechtigte Einwohner nach Alter; Residents entitled to live by age)
Wir schauen uns im Folgenden die Anzahl der Einwohner über die letzten 20 Jahre an.
data <- get_lis_pop(rubrik_nr = 1)Data exploration
Der importierte Datensatz enthält 26 Spalten und 22 Zeilen. Die Variablen haben die folgenden Namen:
colnames(data)
#> [1] "KENNZIFFER" "EINHEIT" "2000" "2001" "2002"
#> [6] "2003" "2004" "2005" "2006" "2007"
#> [11] "2008" "2009" "2010" "2011" "2012"
#> [16] "2013" "2014" "2015" "2016" "2017"
#> [21] "2018" "2019" "2020" "2021" "2022"
#> [26] "2023"Da es sich bei den im Datensatz enthaltenen Angaben um Zähldaten
handelt, ist die Angabe einer Einheit nicht sinnvoll. Folgerichtig
enthält die Variable EINHEIT keine Werte und kann somit
gelöscht werden.
Die Variable KENNZIFFER gibt die Bedeutung der im Datensatz enthaltenen Datenreihen wieder.
data$KENNZIFFER
#> [1] "Bev<U+00F6>lkerung insgesamt" "M<U+00E4>nner"
#> [3] "Frauen" "Deutsche"
#> [5] "M<U+00E4>nner" "Frauen"
#> [7] "Ausl<U+00E4>nder" "M<U+00E4>nner"
#> [9] "Frauen" "Bev<U+00F6>lkerung insgesamt"
#> [11] "M<U+00E4>nner" "Frauen"
#> [13] "Deutsche" "M<U+00E4>nner"
#> [15] "Frauen" "Ausl<U+00E4>nder"
#> [17] "M<U+00E4>nner" "Frauen"
#> [19] "Einwohner mit Migrationshintergrund" "M<U+00E4>nner"
#> [21] "Frauen" "Einwohner mit Nebenwohnsitz"Leider sind die Angaben nicht eindeutig, sodass einige Nacharbeiten erforderlich sind.
Data wrangling
Im folgenden Code-Block werden zwei neue Variablen erzeugt. Die
Variable QUELLE bezeichnet die Herkunft der Daten; die
ersten neun Zeilen enthalten Angaben des “Statistischen Landesamtes
Sachsen”, die Zeilen 10 bis 18 geben die Anzahl der Einwohner mit
Hauptwohnsitz und die Zeilen 19 bis 27 geben die Anzahl der Einwohner
mit Haupt- oder Nebenwohnsitz wieder. Diese Angaben stammen vom
Leipziger Melderegister. Die Variable HERKUNFT gibt an, ob
sich die Zahlen auf Deutsche oder Ausländer beziehen. Abschließend
werden die Angaben aus den Variablen KENNZIFFER und
HERKUNFT in der Variable KENNZIFFER
zusammengefasst. Die Variable HERKUNFT wird nun nicht mehr
benötigt.
data <- data %>%
mutate(
QUELLE = c(
rep("Statistisches Landesamtes Sachsen", 9),
rep("Leipizger Melderegister\n(Hauptwohnsitz)", 12),
rep("Leipizger Melderegister\n(Haupt- oder Nebenwohnsitz)", 1)
),
HERKUNFT = c(rep(c(
rep("Gesamt", 3),
rep("Deutsche", 3),
rep("Ausl<U+00E4>nder", 3)
), 2), rep("Migrationshintergrund", 3), "Nebenwohnsitz"),
KENNZIFFER = str_extract(KENNZIFFER, "^\\w+"),
KENNZIFFER = str_replace(KENNZIFFER, paste(c(
"Deutsche", "Ausl<U+00E4>nder",
"Einwohner mit Migrationshintergrund"
), collapse = "|"), "Gesamt"),
KENNZIFFER = paste(KENNZIFFER, HERKUNFT, sep = ": ")
) %>%
relocate(QUELLE, KENNZIFFER) %>%
select(-HERKUNFT)Da uns zunächst nur die Angaben zur Gesamtbevölkerung interessieren,
wird ein entsprechender Filter gesetzt. Mit der
tidyr::pivot_longer() Funktion wird aus dem vorliegenden
flachen ein tiefer Datensatz gemacht. Die Jahresangaben werden vom
String “JAHR_” befreit und in das Format numeric
umgewandelt.
data.sub <- data %>%
filter(stringr::str_detect(KENNZIFFER, "lkerung: Gesamt")) %>%
pivot_longer(
cols = matches("\\d{4}"),
names_to = "Year",
values_to = "Residents"
)Abschließend lassen sich die Daten mit dem ggplot2-Paket
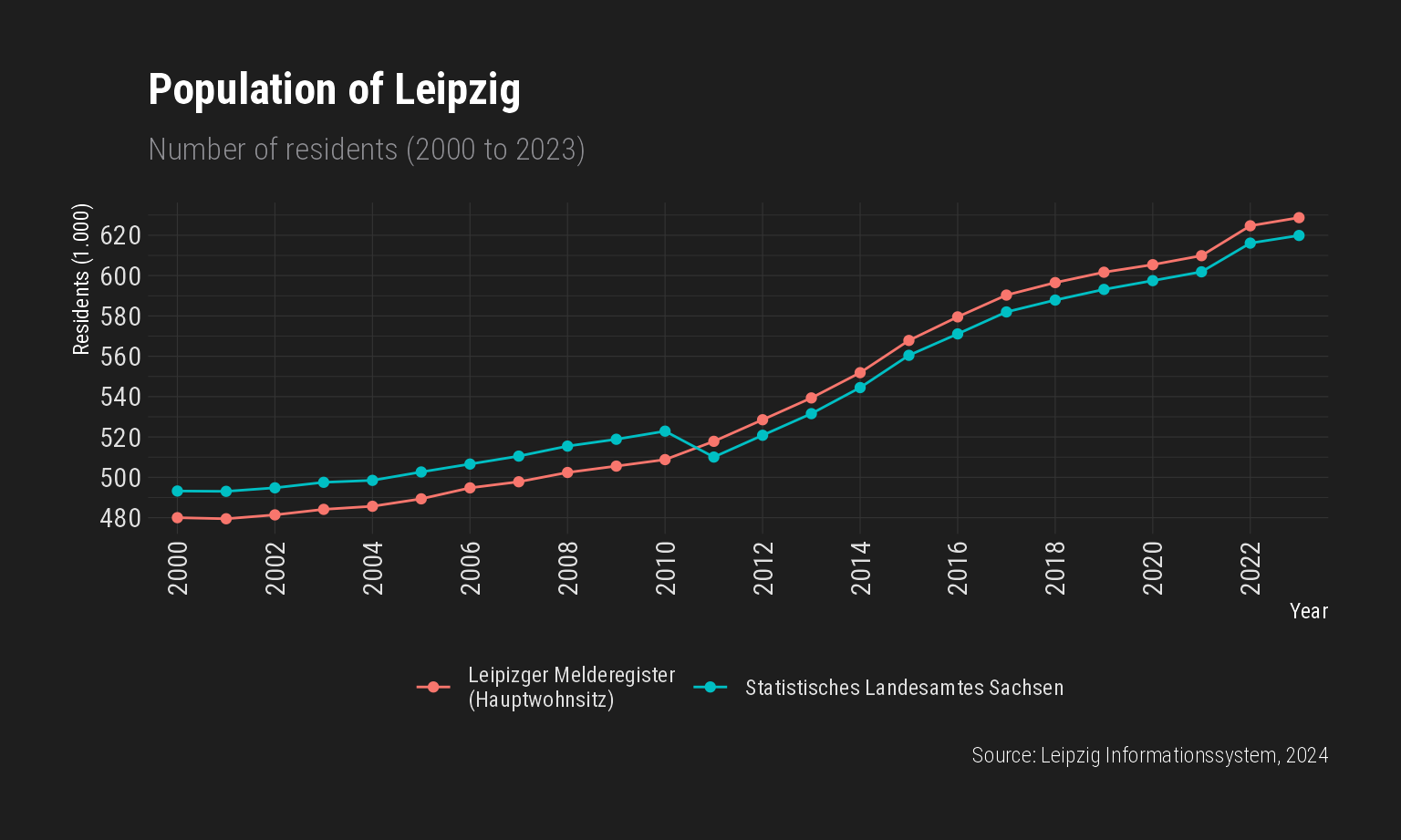
visualisieren. Betrachtet man nur die Einwohner mit Hauptwohnsitz, so
wuchs deren Anzahl in den letzten 20 Jahren von etwa 480.000 auf etwa
600.000, was einer Zunahme um 25 Prozent entspricht.
Data visualisation
ggplot(data.sub, aes(
x = Year,
y = Residents / 1000,
colour = QUELLE
)) +
geom_line(aes(group = QUELLE)) +
geom_point() +
scale_x_discrete(breaks = seq(2000, 2024, 2)) +
scale_y_continuous(breaks = seq(480, 670, 20)) +
hrbrthemes::theme_modern_rc() +
theme(
legend.position = "bottom",
axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)
) +
labs(
colour = NULL,
y = "Residents (1.000)",
title = "Population of Leipzig",
subtitle = "Number of residents (2000 to 2023)",
caption = "Source: Leipzig Informationssystem, 2024"
)